

Introduction
我們都知道 AWS LoadBalancer Controller 有個很嚴重的問題,就是當我們 trigger 一個 release 的時候,一般情況下 Pod 會被 Terminated 而且 draining from ALB Target Group。這就會導致 更新不平滑,因為新的 Pod 還沒 ready 也還沒 healthy(在 Target Group),流量就會進來,那當然就會出現 502。
白話來說,就是更新不平滑,導致的原因就是 ALB Target Group 的狀態跟 Pod 並沒有連動。
本文適用以下情況:
- 在 Target Group 裡永遠只有一個 Pod
- Rollout Strategy 是一次把所有 Pod 全部替換
- Rolling Update 的速度太快
- 或是任何 Target Group 裡可能會暫時沒有
Healthy Pods的情況
Issue
我們來看看時間軸以及 ALB Target Group 和 Kubernetes 如何處理的。
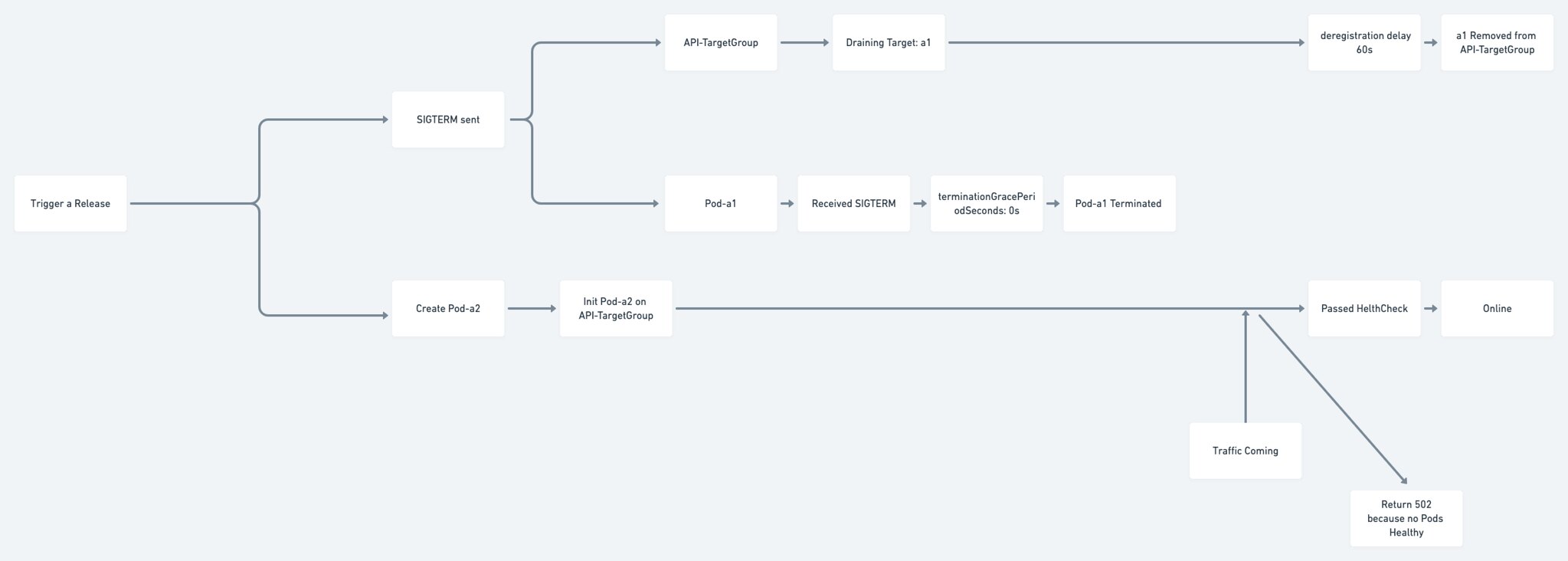
有兩個問題:
- 明顯的,Pod-a1 在 Pod-a2 ready 前就已經開始 draining,如果 Pod 的數量多並且 rolling update 的速度比較慢或許不容易察覺,但是當 Pod 的數量只有 1 或是 rolling update 是一次把所有 Pods 全部替換掉的時候就很明顯了,ALB 就直接給你個 502。
原因就是因為
如果沒有任何 healthy targets 在 Target Group,那 ALB 就還是會將 Traffic 送到 Unhealthy 或是正在啟動的 Pod,那想當然 ALB 就會將 traffic 送到你正在啟動 healthcheck 的 Pod 了。
- Application 還在處理事情就 Pod 直接被 Terminated。
要調整 Pod Lifecycle Termination 的時間,也就是可以等待 Application 做完事情再 Terminate Pod。
Solution
綜合兩個問題要解決的是:
- 讓 New Target 通過 HealthCheck 後再接受流量
- 不要一開始就 Draining Old Target
那這個問題換言之就是要讓 先讓新的 Pod Ready 再去 Draining 舊的 Pod 。
這時候就需要用到 AWS LoadBalancer Controller 的一個新功能了,也就是 Pod Readiness Gate。
這是什麼? 簡單來說這是可以讓 Pod 狀態跟 Target Group 連動的一個 feature。
如果啟用了 Readniness Gate,舊的 Pod 會等到新的 Pod 在 Target Group 是 healthy 的狀態再去 Draining & Terminating 舊的 Pod。

那整個過程就很平滑了,當 Release 觸發的時候 Pod 不會立即接受到 SIGTERM ,而是會等到新的 Pod Healthy 再去發送 SIGTERM。
如何使用?
使用方式很簡單,在目標 Namespace 加上一個 Label 就啟用了。
...(skip)
metadata:
labels:
elbv2.k8s.aws/pod-readiness-gate-inject: enabled
他實現的原理是會讓 AWS LoadBalancer Controller 去輪詢 TargetGroup 的狀態,等到 new Pod healthy 才會做替換的動作。
Issue Solved?
上面的解法聽起來很完美,但是有注意到嗎? Pod Terminated 的比 Draining 還要早,如果我們有一些還沒有處理完的任務,這樣一搞就直接中斷了,還是會有 502 的機率。
因為 一旦新 Pod Healthy 之後馬上會送 SIGTERM 到舊的 Pod,舊的 Pod 接收到就立即執行 Terminate。
要解決這問題,只要 延長 Pod Terminating 的時間 就可以了,Terminating 務必比 Target Group Deregistration Delay 還有 Application Keepalive 的時間長,確保事情都有做完。
Application Keepalive 因為每個 Application 不一樣,就不贅述。 那延長 Pod Terminating 的時間要怎麼做?
我們可以利用 Kubernets Lifecycle PreStop Hook。
https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/
顧名思義,就是在送出 SIGTERM 跟真正終止 Pod 之間要執行的任務,我們可以讓他 sleep 一段時間來延長 Pod 的終止時間。
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 100s"]
但是因為 Kubernetes 還有個東西叫做 terminationGracePeriodSeconds,他會看傳送 SIGTERM 之後過了多久,如果超出設定值,那就會直接強制 Kill Pod。
而這個值預設是 30s。 所以如果 preStop hook sleep seconds > terminationGracePeriodSeconds ,那 Pod 就會提前被 Killed。
那我們就是要確保 terminationGracePeriodSeconds 大於我們 Sleep 的時間就可以了。
整體來說設定要是這樣的:
terminationGracePeriodSeconds > preStop sleep time > ALB deregistration delay > Application KeepAlive time > ALB Idle Timeout
最後的流程應該是像這樣的
Conclusion
簡單來說要解決這個問題就是以下方式:
- 使用 Readiness Gate (在 Namespace 加上 Label 去啟用)
- 加上 preStop lifecycle hook
- 加上 terminationGracePeriodSeconds
- 配置好 health check 時間以及 Deregistration Delay 還有 Idle Timeout
- terminationGracePeriodSeconds > preStop sleep time > ALB deregistration delay > Application KeepAlive time > ALB Idle Timeout



